冬休みの自由研究は、OCRを作ってみることにした。世間一般のOCRは、キャプチャに出てくるような文字をいかに高精度に認識できるかに関心がある感じだけど、ビジネスへの適用だと、以下みたいな限定的な条件を課すかわりにより精度を上げられた方がメリットがあるように考えた。
- 1行分の数字列を認識する。
- 認識するのは、手書きなどは除外でマシン・プリントに限定。
- 基本は数字列のみが認識できれば良い。
- 文字は、等幅フォントを仮定して良い。
実装は、まずイメージ処理で数字列から各数字を分離する。まずy方向で数字列がある領域を探す。これは黒い部分の濃度が高い部分が、しきい値を超えて固まっている部分を抜き出すことで行う。
次にx方向で数字ごとに分離する。これは、各数字の高さに対する幅の比率に仮定(今回は、50-90%)を置くことで、その範囲で各数字の分離を試みて分離境界位置の黒成分が最も少ないところで切り取る。等幅である仮定を置くことで、より高い精度で分離が可能になる。
あとは、ニューラルネットで学習したモデルを使って、分離した各数字を判定する。今回はdeepLerning4jを使用した。教師データは、とりあえずMNISTを使用した。MNISTは手書き文字なので、印字フォントだとあまり精度が出なさそうだけど、とりあえず今回は実装時間を優先。
サンプル・コードは、Dockerizeしてdocker hubでビルドしたので、Dockerがあれば簡単に試すことができる。コードは、数字の分離だけを行う機能と、ocrまで行う機能を作成した。ソースはこちら。
数字の分離は以下で行える。
$ docker run -it --rm -v /tmp:/tmp ruimo/lightocr split /tmp/005.png
引数に、pngで処理したいイメージファイルを指定する。Dockerコンテナ内から見えるようにボリューム指定が必要(-v /tmp:/tmp)。例えば以下のようなイメージを用意した場合、
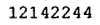
/tmp/005の下に、以下のイメージが生成される。
/tmp/005/000.png: 
/tmp/005/001.png: 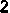
/tmp/005/002.png: 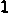
/tmp/005/003.png: 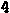
/tmp/005/004.png: 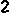
/tmp/005/005.png: 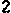
/tmp/005/006.png: 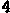
/tmp/005/007.png: 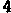
OCRの実行は以下で行える。
$ docker run -it --rm -v /tmp:/tmp ruimo/lightocr ocr /tmp/005.png
引数に、pngで処理したいイメージファイルを指定する。Docker内から見えるようにボリューム指定が必要(-v /tmp:/tmp)。例えば上記のイメージを用意した場合、
/tmp/005.txtにOCRで認識した数字列が生成される。
32392242
毎回、MNISTをダウンロードして学習してから認識に入るのでそれなりに時間がかる。
やはりMNISTが教師データなので精度はいまいちだが、印字文字を集めて学習すれば良くあるMNISTによる認識よりも高い精度が得られそうだ。また、業務で使用するプリンタが限定できるなら、そのプリンタに特化した教師データを集めれば、より高い精度が得られるはず。
教師データ揃えて、学習や認識をRESTで行えるところまでやりたかったけど、今回は時間切れ。